Tesseract是一个开源文本识别(OCR)引擎,免费且多平台可以使用,项目,安装
Windows下使用指南
下载最新版exe文件
安装时注意路径最好不要有中文,其他全选下一步,进入安装文件夹Tesseract-OCR,这里路径是D:\OCR\Tesseract-OCR
下载训练数据,这里使用,这个数据集识别较准确但速度较慢。全部下载文件较大,可以只下载需要用到的语言,这里我下载了 chi_sim.traineddata, chi_sim_vert.traineddata 和 eng.traineddata 三个文件,将文件保存到 D:\OCR\Tesseract-OCR\tessdata中
必须要下载chi_sim_vert否则识别中文报错
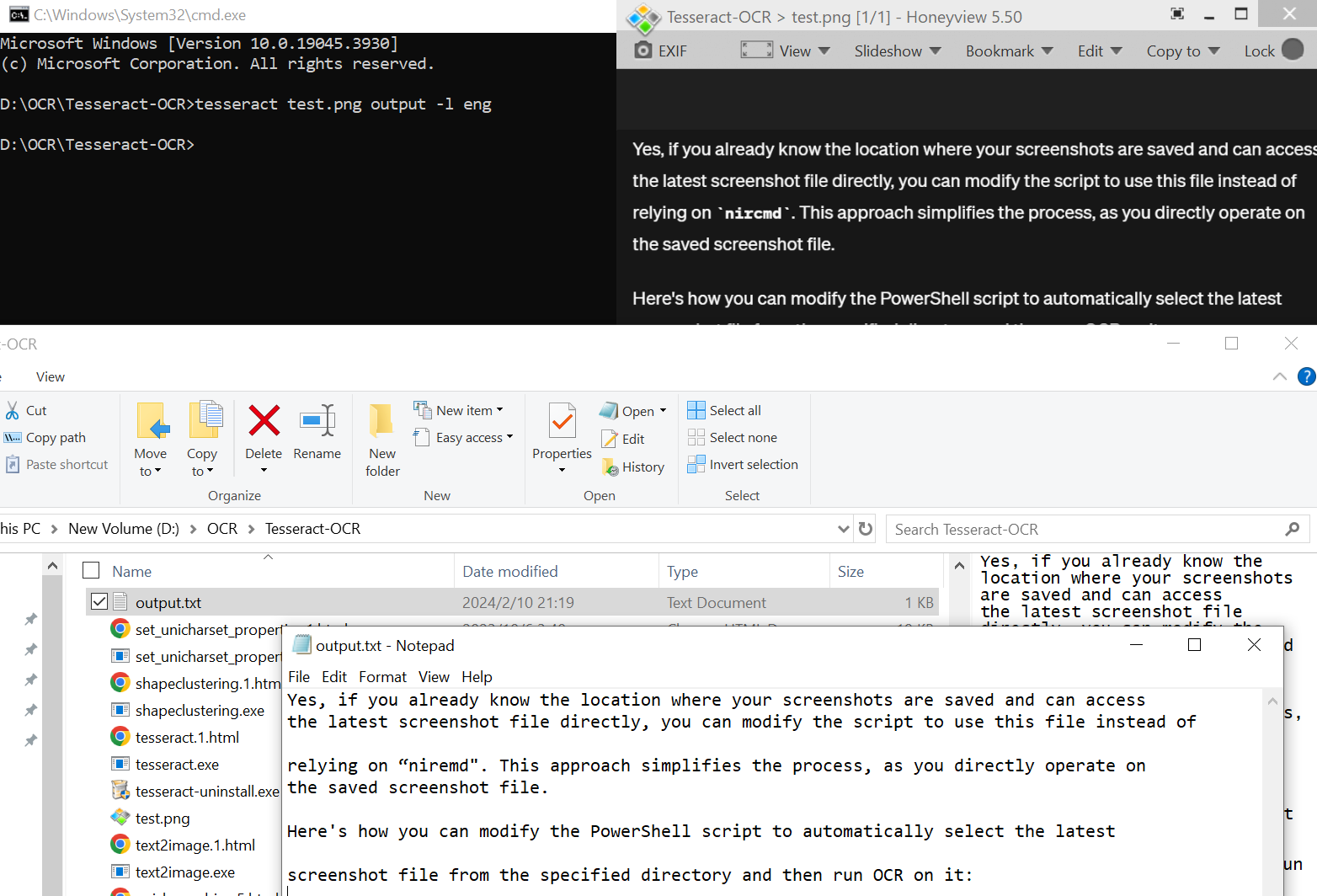
保存一张图片test.png到Tesseract-OCR文件夹,并在该路径下打开cmd 输入以下指令
tesseract test.png output -l eng
这里test.png是输入图片,output是输出的文件output.txt,-l 选择语言为eng,中文参数chi_sim
没有下载chi_sim_vert会报错,根据,使用chi_sim会加载vert,也就是说没有vert是不完整的,两个都有才能识别中文

使用体验:英文识别准确率高,中文一般
OCR识别截图的脚本
至此可以使用命令调用tesseract进行文字识别了,OCR在电脑上的日常使用场景一般为识别图片中的文字,但是上述方法使用起来较麻烦,需要保存识别区域图片,将图片复制到Tesseract文件夹再输入命令。这里写了一个脚本更方便快捷的使用,Windows中,快捷键Win+Shift+S可以框选截图,可以直接粘贴截图或通过Win+V预览剪切板查看截图,该图片的默认保存路径为
C:\Users\XXXX\AppData\Local\Packages\MicrosoftWindows.Client.CBS_XXXXXXX\TempState\ScreenClip
截图后会在该文件夹内生成两张新的图片,一张为原始截图,另一种是压缩后的预览截图,这个只需要找到该文件夹中倒数第二张修改的png图片即可(最新的图片是压缩后的预览图)
创建文件”EngOCR.ps1″,修改下面的screenshotDir,tesseractPath为你的文件路径
# Define the directory where screenshots are saved $screenshotDir = "C:\Users\XXXX\AppData\Local\Packages\MicrosoftWindows.Client.CBS_XXXXXXX\TempState\ScreenClip" # Define the output path for the OCR text file on the desktop $outputPath = [System.IO.Path]::Combine([Environment]::GetFolderPath("Desktop"), "ocr") # Define the path to the Tesseract executable $tesseractPath = "D:\OCR\Tesseract-OCR\tesseract.exe" # Find the penultimate PNG file in the screenshot directory $penultimateScreenshot = Get-ChildItem -Path $screenshotDir -Filter *.png | Sort-Object LastWriteTime -Descending | Select-Object -Skip 1 -First 1 # Check if a screenshot exists if ($penultimateScreenshot -ne $null) { $screenshotPath = $penultimateScreenshot.FullName # Run Tesseract OCR on the penultimate screenshot and save the output text to a file on the desktop & $tesseractPath $screenshotPath $outputPath -l eng # Convert .txt file path for opening or further processing $txtOutputPath = $outputPath + ".txt" # Optional: Open the OCR result with notepad (or your preferred editor) notepad $txtOutputPath } else { Write-Host "No screenshot found in the specified directory." }
截图后使用PowerShell运行该脚本,它会找到截图图片,执行& $tesseractPath $screenshotPath $outputPath -l eng 将识别结果保存到桌面的”ocr.txt”文档中并打开;识别中文可以再写个脚本”ChiOCR.ps1″,将参数eng 修改成chi_sim即可,使用时运行对应语言脚本